LLM-Wiki: la idea de Andrej Karpathy para construir un cerebro digital con IA
- hace 21 horas
- 16 min de lectura
Hay ideas que no parecen espectaculares a primera vista, pero que cuando las piensas un poco empiezan a hacer ruido en la cabeza. La idea de LLM-Wiki, publicada por Andrej Karpathy en abril de 2026, es una de ellas.
No estamos hablando de un nuevo modelo, ni de una aplicación cerrada, ni de otro producto mágico de inteligencia artificial. La propuesta es mucho más sencilla: usar un LLM para construir y mantener una wiki persistente a partir de nuestras fuentes de información.
Dicho de otra forma: en vez de tener una carpeta llena de documentos y preguntarle cosas a la IA cada vez que queremos encontrar algo, dejamos que la IA vaya construyendo una especie de cerebro digital sobre esos documentos.
Una base de conocimiento viva.
Una wiki en Markdown.
Un mapa de conceptos, fuentes, relaciones, contradicciones y síntesis.
Durante los últimos años nos hemos acostumbrado a trabajar con documentos e IA de una forma muy concreta: subimos un PDF, una carpeta de archivos o unas notas, y después le hacemos preguntas al modelo. El sistema busca fragmentos relevantes, los mete en contexto y genera una respuesta.
Ese patrón es lo que normalmente conocemos como RAG, por Retrieval-Augmented Generation. RAG ha sido, y sigue siendo, una forma muy útil de conectar modelos de lenguaje con conocimiento externo. Pero tiene una limitación importante: muchas veces, cada pregunta empieza casi desde cero.
Si hoy preguntamos algo complejo sobre veinte documentos, el sistema busca, recupera, conecta y responde. Si mañana preguntamos otra cosa relacionada, vuelve a hacer una parte importante del mismo trabajo. Puede funcionar bien, pero no necesariamente acumula comprensión, no deja construido un mapa, no mantiene una memoria organizada del tema.
Ahí es donde entra la propuesta de Karpathy. La idea de LLM-Wiki no consiste solo en preguntarle cosas a una carpeta de documentos. Consiste en pedirle al LLM que construya una wiki persistente sobre ellos: una capa intermedia entre las fuentes originales y nuestras preguntas. Las fuentes siguen estando ahí. No se sustituyen, pero por encima aparece una representación organizada, enlazada y mantenida por IA de todo lo que vamos aprendiendo.
Esa es la diferencia clave:
Un RAG tradicional busca fragmentos relevantes en el momento de la pregunta.
Una LLM-Wiki compila conocimiento antes de la pregunta, lo organiza, lo enlaza y lo mantiene vivo.
Y eso, aunque parezca una diferencia pequeña, cambia bastante la forma de trabajar con información.

El problema: tener documentos no significa tener conocimiento
Todos hemos vivido alguna versión de esto: una carpeta llena de PDFs, un historial de correos, notas de reuniones, artículos guardados “para leer más tarde”, capturas, enlaces, informes, transcripciones y documentos que, en teoría, contienen todo lo que necesitamos saber.
El problema es que tener la información no significa tener el conocimiento. La información puede estar ahí, pero dispersa. Una idea importante puede estar escondida en un párrafo. Una contradicción puede aparecer entre dos documentos que nadie ha comparado. Una decisión puede haberse tomado en una reunión y quedar enterrada en una transcripción. Un concepto puede ir evolucionando con el tiempo sin que exista una página que explique claramente en qué punto estamos, y cuando volvemos semanas después, toca reconstruir el contexto otra vez.
Aquí es donde muchas soluciones basadas en IA documental ayudan bastante. Podemos subir archivos, preguntar cosas y obtener respuestas rápidas. Pero en muchos casos el sistema sigue trabajando sobre fragmentos sueltos. Recupera trozos de información, los combina y genera una respuesta.
Eso está bien para muchas preguntas. Pero no siempre es suficiente cuando lo que necesitamos no es solo encontrar un dato, sino entender cómo se relacionan las cosas.
La propuesta de LLM-Wiki apunta justo a ese hueco: pasar de una carpeta de documentos a una estructura de conocimiento. No se trata solo de buscar mejor. Se trata de construir una memoria organizada sobre lo que ya hemos leído, preguntado, resumido y conectado.

Qué es exactamente una LLM-Wiki
Una LLM-Wiki es una base de conocimiento persistente mantenida por un modelo de lenguaje.
Dicho así puede sonar un poco abstracto, pero la idea es bastante sencilla. Imagina una wiki normal, con páginas, enlaces internos, resúmenes, conceptos, índices y referencias. Ahora imagina que no tienes que escribirla y mantenerla tú manualmente, sino que el LLM se encarga de ir construyéndola a partir de las fuentes que le vas dando.
Tú aportas los documentos, tú haces las preguntas y tú decides qué es importante, pero es el modelo el que hace el trabajo pesado: resumir, ordenar, crear páginas, actualizar conceptos, enlazar ideas, detectar contradicciones y mantener la estructura viva.
La wiki deja de ser una carpeta estática de notas y se convierte en una capa de conocimiento mantenida por IA, y aquí está la parte importante: esa wiki no desaparece cuando termina la conversación. Las respuestas interesantes, las relaciones entre documentos, las síntesis útiles y los conceptos importantes pueden quedar escritos en archivos Markdown. Pueden revisarse, corregirse, ampliarse y volver a utilizarse más adelante.
En ese sentido, una LLM-Wiki no es solo una herramienta para responder preguntas. Es una forma de convertir conversaciones, documentos y análisis en una memoria persistente. Karpathy lo explica con una analogía muy buena: Obsidian sería el IDE, el LLM sería el programador y la wiki sería el código base.
La comparación encaja bastante bien, porque igual que el código se puede revisar, versionar, refactorizar y mejorar, una wiki en Markdown también puede evolucionar con el tiempo. No es una respuesta perdida en un chat. Es un artefacto que queda. Un pequeño cerebro digital que va creciendo fuente a fuente, pregunta a pregunta y conexión a conexión.
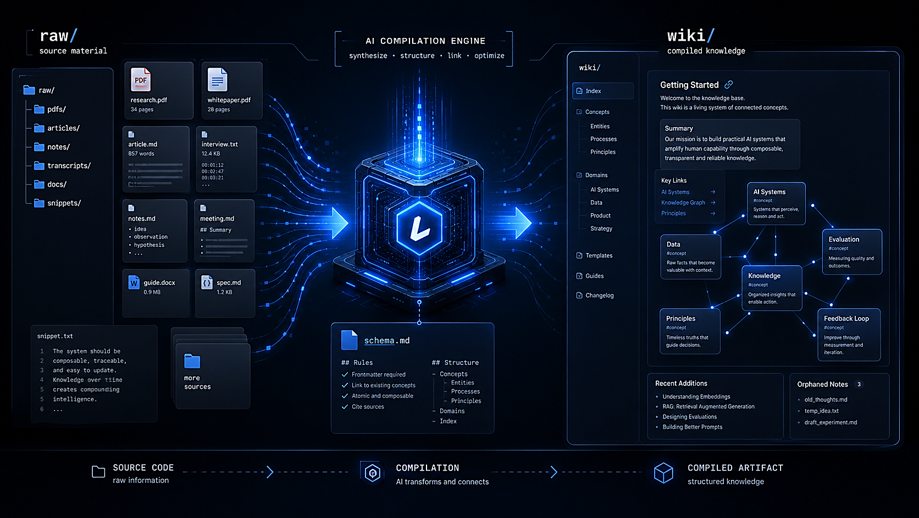
La arquitectura básica: fuentes, wiki y reglas
La propuesta de Karpathy no empieza por una plataforma complicada, no hace falta imaginar una arquitectura enorme, con bases de datos vectoriales, servidores, dashboards y veinte herramientas conectadas. La idea base se puede entender con tres piezas muy simples: fuentes, wiki y reglas.
La primera pieza son las fuentes originales.
Aquí irían los documentos brutos: artículos, PDFs, notas, transcripciones, páginas web, informes o cualquier otro material que queramos usar como base. En la propuesta de Karpathy, estas fuentes suelen vivir en una carpeta tipo raw/. La idea importante es que esas fuentes no se modifican, son la evidencia original. El LLM puede leerlas, analizarlas y extraer información, pero no debería reescribirlas ni sustituirlas. Si mañana necesitamos comprobar de dónde sale una afirmación, deberíamos poder volver al documento original.
La segunda pieza es la wiki.
Esta es la capa que sí construye y mantiene el LLM. Normalmente estaría en una carpeta tipo wiki/, formada por archivos Markdown: páginas de conceptos, resúmenes, comparativas, índices, síntesis, relaciones entre temas y notas de evolución. Aquí es donde empieza a aparecer el valor. El modelo no solo resume una fuente y se olvida. Puede actualizar una página existente, crear una nueva, añadir enlaces internos, detectar que dos conceptos están relacionados o señalar que una fuente nueva contradice algo que ya estaba escrito.
La tercera pieza son las reglas.
Karpathy propone tener un archivo de instrucciones, algo como schema.md, AGENTS.md o CLAUDE.md, donde se define cómo debe trabajar el LLM: qué estructura debe seguir, cuándo crear páginas nuevas, cómo enlazar conceptos, cómo citar fuentes, cómo actualizar el índice y qué hacer cuando encuentre contradicciones.
Este archivo es más importante de lo que parece. Sin reglas, el LLM es solo un chatbot improvisando, pero con reglas, empieza a comportarse como un mantenedor disciplinado de una base de conocimiento.
Una estructura mínima podría ser algo así:
llm-wiki/
raw/
articulos/
pdfs/
notas/
wiki/
index.md
log.md
conceptos/
resumenes/
comparativas/
schema.md
No es una estructura obligatoria. Es solo una forma sencilla de entender el patrón.
raw/ guarda la información original.
wiki/ guarda el conocimiento organizado.
schema.md le dice al LLM cómo debe transformar una cosa en la otra.
Y esa separación es clave, porque evita mezclar la evidencia con la interpretación.
Las fuentes conservan lo que se dijo.
La wiki conserva lo que vamos entendiendo.
Las reglas mantienen el sistema ordenado.
En el fondo, una LLM-Wiki funciona como una pequeña fábrica de conocimiento: entran documentos dispersos, el modelo los procesa, y sale una estructura navegable que podemos consultar, revisar y seguir ampliando.

Las tres operaciones principales: ingest, query y lint
Una vez entendida la arquitectura básica, la siguiente pregunta es evidente: ¿Cómo funciona una LLM-Wiki en el día a día? Karpathy resume el flujo en tres operaciones principales: ingest, query y lint, o dicho en castellano: ingerir información, consultar conocimiento y revisar la salud de la wiki.
La primera operación es ingest.
Esto ocurre cuando añadimos una nueva fuente al sistema: un artículo, un PDF, una nota, una transcripción o cualquier otro documento. En un RAG tradicional, lo normal sería indexar ese documento para poder recuperarlo más adelante.
En una LLM-Wiki, la idea va un paso más allá. El modelo no solo guarda el documento para buscarlo después. Lo lee, extrae las ideas importantes y las integra en la wiki existente. Puede crear una página resumen, puede actualizar una página de concepto, puede añadir enlaces internos, puede detectar que una idea ya estaba mencionada en otra fuente, y puede señalar que un documento nuevo contradice algo que la wiki decía hasta ahora.
La fuente entra en raw/, pero el conocimiento resultante acaba integrado en wiki/.
La segunda operación es query.
Aquí es donde hacemos preguntas al sistema. Pero la diferencia es que el modelo no tiene que empezar siempre desde los documentos brutos. Puede consultar primero la wiki: el índice, las páginas de conceptos, los resúmenes, las relaciones y las síntesis ya creadas.
Si necesita comprobar un dato concreto, puede volver a la fuente original, pero ya no trabaja únicamente con fragmentos aislados. Trabaja sobre una capa de conocimiento que se ha ido construyendo con el tiempo, y aquí aparece una idea muy potente: las buenas respuestas también pueden guardarse.
Si hacemos una comparación interesante, una síntesis útil o una explicación que aporta valor, esa respuesta puede convertirse en una nueva página de la wiki. Así, nuestras propias preguntas también hacen crecer el sistema.
La tercera operación es lint.
Este concepto viene del mundo de la programación. Un linter revisa el código para detectar errores, incoherencias o problemas de formato. En una LLM-Wiki, el lint cumple una función parecida, pero aplicada al conocimiento.
De vez en cuando podemos pedirle al modelo que revise la wiki y busque problemas: páginas huérfanas, conceptos importantes sin desarrollar, enlaces internos que faltan, afirmaciones antiguas que podrían estar obsoletas, contradicciones entre páginas o zonas de conocimiento poco cubiertas.
Esta operación es clave porque una wiki no se estropea de golpe sino poco a poco. Primero aparece una página que nadie actualiza. Luego dos conceptos duplicados. Después una contradicción que pasa desapercibida. Más tarde, una afirmación antigua sigue pareciendo vigente aunque ya no lo sea.
El lint sirve para evitar que la wiki se convierta en otro almacén desordenado.
Ingest hace crecer la wiki.
Query la convierte en una herramienta útil.
Lint la mantiene sana.
Y cuando las tres operaciones funcionan juntas, la LLM-Wiki deja de ser una simple colección de notas y empieza a comportarse como una memoria viva.

index.md y log.md: el mapa y la memoria del sistema
En una LLM-Wiki hay dos archivos pequeños que pueden marcar una diferencia enorme: index.md y log.md.
No son especialmente sofisticados ni tienen magia, pero ayudan a que el sistema siga siendo navegable cuando la wiki empieza a crecer.
index.md funciona como el mapa de la wiki.
Es el lugar donde se recoge qué páginas existen, de qué trata cada una y cómo están organizadas. Puede tener secciones por conceptos, fuentes, personas, temas, resúmenes o comparativas. Lo importante es que tanto el usuario como el LLM puedan entrar ahí y entender rápidamente qué contiene la base de conocimiento.
Cuando hacemos una pregunta, el modelo puede empezar leyendo el índice. En lugar de lanzarse directamente contra todos los documentos originales, primero mira el mapa y ve qué páginas pueden ser relevantes, entra en ellas y construye la respuesta desde una estructura ya organizada.
Esto parece simple, pero es bastante potente. A pequeña y mediana escala, un buen índice puede evitar mucha infraestructura innecesaria. No siempre hace falta empezar con una base vectorial, embeddings y sistemas de búsqueda complejos. A veces, una wiki bien escrita, bien enlazada y con un índice actualizado ya permite trabajar muy bien.
El otro archivo importante es log.md.
Si index.md es el mapa, log.md es la memoria cronológica del sistema.
Ahí se registra qué ha pasado en la wiki: qué fuentes se han ingerido, qué páginas se han creado, qué conceptos se han actualizado, qué consultas importantes se han guardado y cuándo se han hecho revisiones de mantenimiento.
El índice responde a la pregunta: “¿Qué hay en esta wiki?”
El log responde a otra pregunta igual de importante: “¿Qué ha pasado en esta wiki?”
Porque una base de conocimiento no solo necesita contenido. También necesita historia. Necesita saber cuándo entró una fuente, cuándo se actualizó una síntesis, cuándo se detectó una contradicción o cuándo una página quedó marcada como pendiente de revisión.
En el fondo, index.md y log.md convierten una carpeta de Markdown en algo mucho más útil.
El índice da orientación.
El log da trazabilidad.
Y juntos ayudan a que la LLM-Wiki no sea solo una colección de páginas, sino un sistema que sabe dónde está su conocimiento y cómo ha ido evolucionando.
Por qué esto no es simplemente otra forma de RAG
Llegados a este punto, es fácil caer en una frase demasiado rápida: “Entonces LLM-Wiki sustituye al RAG”, pero no es tan simple y, probablemente, tampoco sería correcto.
RAG sigue siendo una herramienta muy potente. Si tenemos una gran colección de documentos y queremos buscar información concreta, recuperar fragmentos relevantes y responder con apoyo en fuentes, RAG tiene muchísimo sentido.
El problema no es que RAG no sirva. El problema es que RAG trabaja muchas veces en el momento de la pregunta: busca, recupera, combina y responde.
Eso está muy bien cuando necesitamos encontrar algo. Pero no siempre es suficiente cuando lo que queremos es construir una comprensión acumulada de un tema.
Ahí es donde LLM-Wiki propone un enfoque diferente. En un RAG tradicional, la unidad de trabajo suele ser el fragmento recuperado. En una LLM-Wiki, la unidad de trabajo es la página de conocimiento mantenida en el tiempo.
La diferencia es importante. Con RAG, cada pregunta obliga al sistema a reconstruir parte del contexto. Con LLM-Wiki, parte de ese contexto ya está trabajado: los conceptos tienen páginas, las fuentes tienen resúmenes, las relaciones están enlazadas y las contradicciones pueden haber sido detectadas antes.
RAG es muy bueno para encontrar información.
LLM-Wiki intenta ser buena para acumular comprensión.
Por eso no deberíamos plantearlo como una guerra entre dos enfoques. La wiki puede servir como capa de conocimiento organizada, cómoda para navegar, consultar y ampliar. Y el RAG, o cualquier sistema de búsqueda sobre fuentes originales, puede seguir siendo necesario para verificar datos, revisar citas, buscar detalles concretos o trabajar con grandes volúmenes de información.
Dicho de forma sencilla:
La wiki ayuda a pensar.
El retrieval ayuda a comprobar.
Una LLM-Wiki bien diseñada no elimina la necesidad de volver a las fuentes. Al contrario: debería facilitar ese camino. Cada afirmación importante debería poder conectarse con el documento original del que salió. La gracia está en no tener que reconstruir siempre desde cero todo el mapa mental. Si el sistema ya leyó, resumió, enlazó y comparó una serie de fuentes, tiene sentido conservar ese trabajo.
Ese es el cambio de enfoque. No pasar de RAG a no-RAG. Pasar de buscar fragmentos a mantener conocimiento.
La idea de conocimiento compilado
Una forma muy útil de entender LLM-Wiki es pensar en ella como un sistema de conocimiento compilado. La comparación viene del mundo de la programación. Cuando programamos, tenemos código fuente. Ese código se escribe, se organiza, se revisa y después se compila para generar algo que se puede ejecutar de forma más eficiente.
Con una LLM-Wiki pasa algo parecido. Las fuentes originales son el código fuente, la wiki es el artefacto compilado y las reglas del sistema son el proceso que transforma una cosa en la otra.
En la carpeta raw/ tenemos la información original: documentos, artículos, notas, transcripciones, PDFs o cualquier otra fuente. Esa capa conserva la evidencia.
En la carpeta wiki/ tenemos el conocimiento ya procesado: resúmenes, conceptos, enlaces internos, comparativas, contradicciones, síntesis y páginas que explican cómo se relacionan las cosas.
Y en el archivo de reglas tenemos las instrucciones que le dicen al LLM cómo debe hacer esa transformación.
Una de las grandes ventajas de este enfoque: no tenemos que volver siempre al caos documental para reconstruir el contexto. Parte del trabajo ya está hecho. El sistema ya ha leído, resumido, conectado y organizado la información.
Eso no significa que la wiki tenga siempre razón. Significa que tenemos una capa de trabajo mucho más cómoda que la documentación bruta, una capa que podemos consultar, corregir, ampliar y volver a compilar cada vez que entren nuevas fuentes.
No es solo buscar mejor, es procesar mejor, y sobre todo, conservar ese procesamiento para que no se pierda en cada nueva conversación.
Por qué los LLMs encajan tan bien en este trabajo
La idea de LLM-Wiki no funciona porque la IA sea mágica. Funciona porque los LLMs son buenos en una parte del trabajo que a los humanos nos suele dar bastante pereza: mantener ordenado el conocimiento.
Leer un documento puede ser interesante. Pensar sobre una idea también. Hacer buenas preguntas, más todavía. Pero actualizar enlaces internos, revisar si una página se ha quedado obsoleta, detectar conceptos duplicados, mantener un índice o corregir pequeñas incoherencias… eso ya no suele ser tan divertido, y ahí es donde muchas wikis acaban muriendo.
El problema de una base de conocimiento no es crearla. El problema es mantenerla viva. Karpathy apunta justo a ese punto: quizá el humano no debería hacer todo el mantenimiento manual.
El humano aporta fuentes, hace buenas preguntas, revisa lo importante y decide hacia dónde va el análisis.
El LLM resume, clasifica, enlaza, actualiza, compara y propone mejoras.
Ese reparto tiene mucho sentido. No significa dejar al modelo actuar sin control. La supervisión humana sigue siendo necesaria, pero si el coste de mantener el conocimiento ordenado baja muchísimo, la wiki deja de ser una obligación y empieza a convertirse en una herramienta real, no porque el LLM piense por nosotros sino porque nos ayuda a no perder lo que ya hemos pensado.
Markdown, Obsidian y Git: herramientas simples para una idea potente
Una parte interesante de la propuesta de Karpathy es que no empieza por una gran plataforma empresarial. Empieza por algo mucho más simple: archivos Markdown.
Markdown es texto plano. Se puede leer, editar, copiar, versionar y mover entre herramientas sin depender demasiado de una aplicación concreta. No es una base de datos cerrada ni un formato raro. Es una forma sencilla de escribir conocimiento estructurado.
Encima de esos archivos podemos usar herramientas como Obsidian, que permiten navegar la wiki de una forma muy cómoda: seguir enlaces internos, ver backlinks, explorar el grafo de relaciones y moverse entre conceptos como si estuviéramos recorriendo un mapa.
Y si además usamos Git, aparece otra ventaja importante: el historial. Podemos ver qué cambió, cuándo cambió y, si hace falta, volver atrás. Eso convierte la wiki en algo mucho más controlable que una simple colección de notas.
Markdown pone la base.
Obsidian ayuda a navegar.
Git aporta trazabilidad.
El LLM se encarga de mantener la estructura.
No hace falta empezar con una arquitectura enorme. Podemos empezar con una carpeta bien organizada, unas reglas claras y un modelo que vaya construyendo la wiki poco a poco. Luego, si el sistema crece, ya habrá tiempo de añadir búsqueda avanzada, embeddings, bases vectoriales o herramientas más sofisticadas.
Pero la idea inicial es: empezar simple, probar rápido y complicarlo solo cuando haga falta.
Del Memex al cerebro digital
La idea de LLM-Wiki no aparece de la nada. En realidad conecta con una aspiración bastante antigua: construir una memoria externa que nos ayude a guardar, relacionar y recuperar conocimiento.
En 1945, Vannevar Bush imaginó el Memex, una especie de máquina personal para almacenar libros, documentos, registros y notas. Pero lo interesante no era solo guardar información. Lo importante era poder crear caminos entre ideas, rutas asociativas, conexiones y relaciones entre documentos.
Visto desde hoy, el Memex se parece mucho a una versión primitiva de lo que ahora llamaríamos un cerebro digital. Durante décadas hemos tenido muchas herramientas para guardar información: carpetas, bases de datos, wikis, marcadores, gestores de notas, sistemas documentales. El problema casi siempre ha sido el mismo: guardar es fácil; mantener relaciones útiles entre lo guardado es mucho más difícil.
Ahí es donde los LLMs cambian un poco el escenario porque pueden encargarse de una parte del mantenimiento que antes dependía completamente de nosotros. Pueden resumir, pueden enlazar, pueden detectar conexiones, pueden actualizar páginas, pueden señalar contradicciones y pueden proponer nuevas rutas de exploración.
La LLM-Wiki es, en cierto modo, una actualización moderna de esa vieja intuición: no queremos solo almacenar documentos; queremos construir caminos entre ellos., y esos caminos son los que convierten una carpeta de archivos en una base de conocimiento, o dicho de otro modo, los que convierten documentación muerta en memoria útil.

Qué puede salir mal
La idea de LLM-Wiki es potente, pero no conviene idealizarla. Una wiki mantenida por IA puede ser muy útil, pero también puede equivocarse, quedarse obsoleta o contaminarse con información poco fiable.
El primer riesgo es confiar demasiado en la síntesis. Que una página esté bien escrita no significa que sea correcta. El LLM puede resumir mal, interpretar de más o conectar ideas que realmente no estaban tan relacionadas. Por eso las fuentes originales deben seguir estando siempre disponibles. La wiki ayuda a trabajar, pero la evidencia sigue estando en los documentos.
El segundo riesgo es la obsolescencia. Una página puede ser válida hoy y dejar de serlo mañana. Si entra nueva información y la wiki no se actualiza bien, podemos acabar tomando decisiones sobre conocimiento viejo con apariencia de conocimiento actual.
El tercer riesgo es la escala. Karpathy plantea esta idea para una escala moderada. Una wiki pequeña o mediana puede funcionar muy bien con buenos índices, enlaces y revisiones. Pero si crece demasiado, seguramente hará falta añadir búsqueda avanzada, embeddings, grafos o herramientas específicas para no perder control.
El cuarto riesgo es la seguridad. Si la wiki ingiere documentos externos, correos, páginas web o información de terceros, puede entrar contenido malicioso, manipulado o simplemente incorrecto. Y si ese contenido acaba convertido en memoria persistente, el problema ya no vive solo en una respuesta: queda guardado en el sistema.
Por eso una LLM-Wiki no debería ser una caja negra. Necesita fuentes trazables, revisión humana, fechas, niveles de confianza y mecanismos para marcar información dudosa o sustituida.
La idea no es construir una wiki que “siempre tenga razón”. La idea es construir una wiki que nos ayude a pensar mejor, pero que también podamos auditar, corregir y mantener bajo control, porque un cerebro digital útil no es el que lo recuerda todo. Es el que sabe distinguir entre memoria, interpretación y evidencia.
Conclusión: de buscar documentos a construir memoria
La idea de LLM-Wiki no consiste simplemente en automatizar una wiki. Consiste en cambiar la forma en que pensamos la relación entre IA, documentos y conocimiento.
Hasta ahora, muchas soluciones de IA documental han funcionado con una lógica bastante clara: tenemos documentos, hacemos preguntas y el sistema busca fragmentos para responder. Eso es útil, pero Karpathy propone dar un paso más: no usar el LLM solo para responder preguntas, sino para construir y mantener una memoria persistente sobre lo que vamos aprendiendo.
La clave está en entender bien el reparto de papeles.
El humano aporta criterio, fuentes, preguntas y supervisión.
El LLM resume, enlaza, actualiza, detecta inconsistencias y mantiene la estructura.
Las fuentes conservan la evidencia.
La wiki conserva la comprensión acumulada.
Cada vez generamos más documentos, más notas, más conversaciones, más informes, más enlaces y más información dispersa, el problema ya no es solo acceder a la información. El problema es no perder el sentido de todo lo que vamos acumulando.
LLM-Wiki apunta justo a ese punto. No se trata de tener más archivos. Se trata de construir mejores caminos entre ellos. No se trata de preguntar una y otra vez sobre el mismo caos documental, se trata de convertir ese caos en una memoria útil, navegable y viva.
Quizá por eso la idea conecta tan bien con la imagen del cerebro digital. No porque la IA piense por nosotros, sino porque puede ayudarnos a no perder lo que ya hemos leído, conectado, resumido y entendido.
En el siguiente artículo llevaremos esta idea a un terreno mucho más concreto: la gestión de proyectos, porque es un entorno donde la información se dispersa rápido, cambia constantemente y necesita contexto histórico, es precisamente un proyecto real. Actas de reunión, decisiones, riesgos, cambios, requisitos, documentos técnicos, correos, informes, pendientes y conversaciones van construyendo una historia que muchas veces nadie tiene completa en la cabeza.
La pregunta es evidente: ¿qué pasaría si pudiéramos convertir todo ese material de un proyecto en una memoria viva del proyecto?
Una LLM-Wiki no sustituiría al project manager, ni a los sistemas oficiales, ni a la documentación contractual. Pero podría convertirse en una capa de conocimiento operativo: un lugar donde entender qué ha pasado, qué está conectado, qué decisiones siguen vivas y qué información merece volver a revisarse.
Eso será lo que exploraremos en nuestro siguiente artículo sobre el LLM Wiki.




















Comentarios